
BASIC MACHINE LEARNING TERMINOLOGY
To enter the world of automatic learning, it is necessary to know its basic thermology because this will allow a better understanding of the problems and in front of so much data we receive from our database, we must know that columns and rows are also intended to separate the different information to give the relevant treatment.
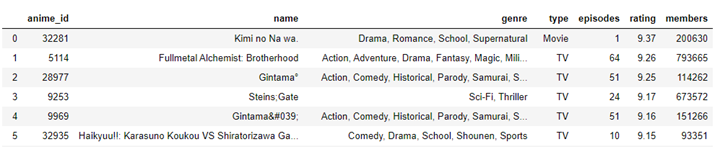
In order to explain the above we will use an anime database provided by Amazon Web Service and can be found at the following link: https://shared-files-lya.s3.amazonaws.com/Test+Assets/anime.csv
LABEL:
It is the value we are predicting, that is, the variable “y”. In the simple linear regression, the label could be the future value we are predicting and, in the classification, it could be the type of garment shown in an image. In our case the label in our database is the rating achieved by the anime.
ATTRIBUTE:
An attribute is an input variable, that is, the x variable in the simple linear regression. A simple machine learning project might use a single attribute, while a more sophisticated one might use millions of attributes, specified as: x1, x2, x3… xn.
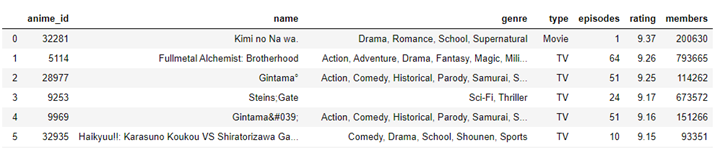
In our database example, the attributes could include the following:
- anime_id.
- name.
- genre.
- type.
- Episodes.
- members.
EXAMPLE:
An example is a particular data instance, X. (The x is capitalized to indicate that it is a vector.) The examples are divided into two categories:
- labeled examples (A labeled example includes both attributes and the label, labeled examples: {features, label}: (x, y))
- unlabeled examples: {features, ? }: (x, ?)
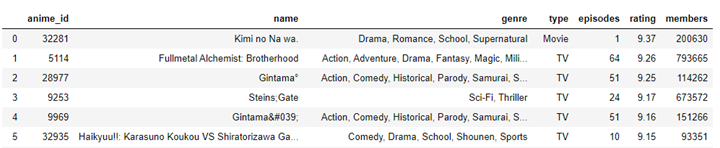
In our case as it is a supervised training linear regression model, our automatic learning algorithm will be trained using the labels and our example would be the following vector.
MODEL:
A model defines the relationship between the attributes and the label. For example, the relationship between the number of episodes and the rating or the genre to which the anime belongs and the rating.
- Training means learning the model. That is, showing tagged examples to the model allows the model to gradually learn the relationships between the attributes and the tag through the different existing Machine Learning algorithms.
- Inference means applying the trained model to unlabeled examples. That is, you use the trained model to make useful predictions (and’). For example, during inference, as mentioned above you can predict the rating for new unlabeled examples.
Posted by

Felipe Gonzalez – Python Developer