
FUNDAMENTALS OF DATA PREPROCESSING FOR MACHINE LEARNING ALGORITHM TRAINING
The predictive models of Machine Learning are really mathematical and statistical algorithms which, through the processing of a data, adjusted some hyperparameters to be able to respond to the problem posed by said data specifically, this means that the Machine Learning algorithm must “learn” from the data that is supplied to it, these algorithms are mathematical formulas that model a statistical system, this statistical model understands a language, the language of numbers, this means that the data with which we are going to train our Machine Learning algorithm must be numbers, but in most cases, the data we collect is not in numerical form but comes categorically or in words, we already mentioned that this type of data our algorithm does not understand, cannot process, for that there is a step in the Machine Learning flow called “Data Preprocessing”.
Data preprocessing is the action of modifying and/or adjusting our data (keeping the original sense) collected in a way that our Machine Learning algorithm can understand, for this purpose there are several techniques that we are going to follow.
From Categorical to Numeric
It consists of translating data from words or categories to numbers, of this there are several types.
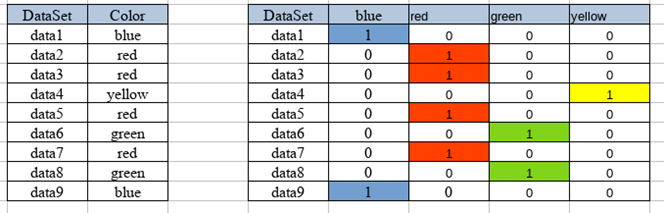
Dummies: consists of passing several categories to a binary matrix, for example, we have a column called colors (red, blue, yellow, and green) which we convert to a binary matrix.
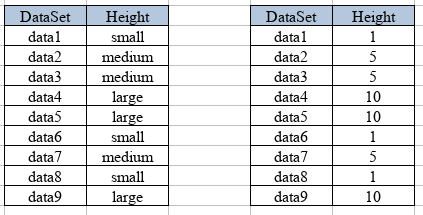
Escalate: When we have categories of magnitude, for example, we have a classification by size (low, medium, and high) numbers are assigned that represent these values.
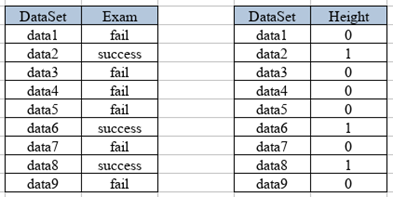
• Binary Category: Very similar to scalar but only with two classifications, for example, those who passed an exam or want to have lost it.
Missing data
One of the biggest enemies of the precision (accuracy) of Machine Learning models is the missing data since the algorithm can take it as one more category when in fact they are errors of our DataSet, for that there are several techniques to deal with them:
• We can eliminate the columns with missing data, as long as it is not a significant percentage of our DataSet.
• We can include the missing data as yet another category of our DataSet.
• We can extrapolate and interpolate values, we can use statistics to fill in the missing values.
• The missing values can be filled with central tendency values such as the mean, the average, or the mode, as long as the DataSet allows it.
Atypical Data:
Atypical data are those that do not follow the general pattern of the DataSet and these can affect the training of our model, it is recommended that these outliers be eliminated, there are different techniques to detect this type of atypical data.
• range of permissibility of the standard deviation: for them, we must find the average (p), then we must find the standard deviation (v), and finally the range will be an amplitude (A) for our standard deviation +/- our average m of [p-Av, p + Av]
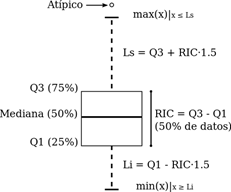
• Interquartile range: for this, the quartiles Q1 and Q3 of our DataSet are found, then the interquartile range is calculated which is Q3-Q1 = RIC then my outlier data will be x <Q1 – A (RIC) or x> A (RIC), generally the amplitude in these cases is 1.5.
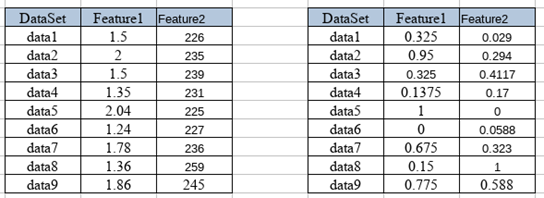
Normalize data
On some occasions, we find a DataSet that in its different Features has very distant values and this can affect the performance of our model in several ways, mainly in the computational cost and in the precision of the training, so what is done is to normalize the values leading to a range between zero and one (0-1) using the formula.
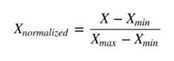
Posted by

Felipe Gonzalez- Data Science Developer