
SUPPORT VECTOR MACHINE
The support vector machine is one of the most popular classification algorithms. This algorithm was developed in the ’90s, within the field of computational science by Vladimir Vapnik. The SVM has good precision and its predictions are faster than the Naive Bayes algorithm.
Some of its applications are:
• Face detection
• Intruder detection
• Classification of emails
• Image recognition on board satellites
But what does this algorithm consist of? How does it work?
In a concise way, the SVM is a model that represents the sample points in space, separating the classes, to 2 spaces as wide as possible, by means of a separation hyperplane defined as the vector between 2 points of the two classes, to which it is called: support vector. In the case of a two-dimensional space, a hyperplane is a line that divides the plane into two halves.
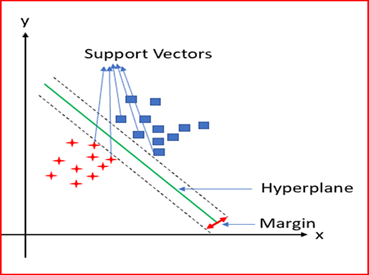
This is what our model would look like, in case a linear separation is possible. But what if it is not possible to separate the data linearly?
To solve this, there is something called “The Kernel Trick”, which consists of “inventing” or increasing a new dimension in which we can find a hyperplane to separate the classes.
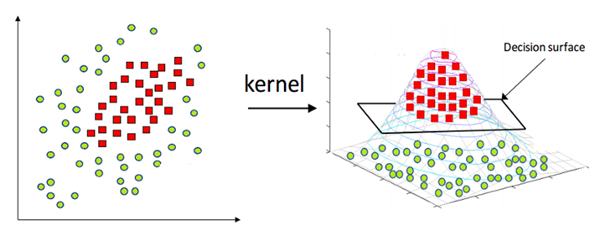
In essence, what the kernel trick does for us is to offer a more efficient and less expensive way of transforming data in higher dimensions. That being said, applying the kernel hack is not limited to the SVM algorithm. Any computation involving the scalar products (x, y) can use the kernel trick.
Posted by

Melissa Álvarez – Systems Engineer